Let's Imagine a Case:
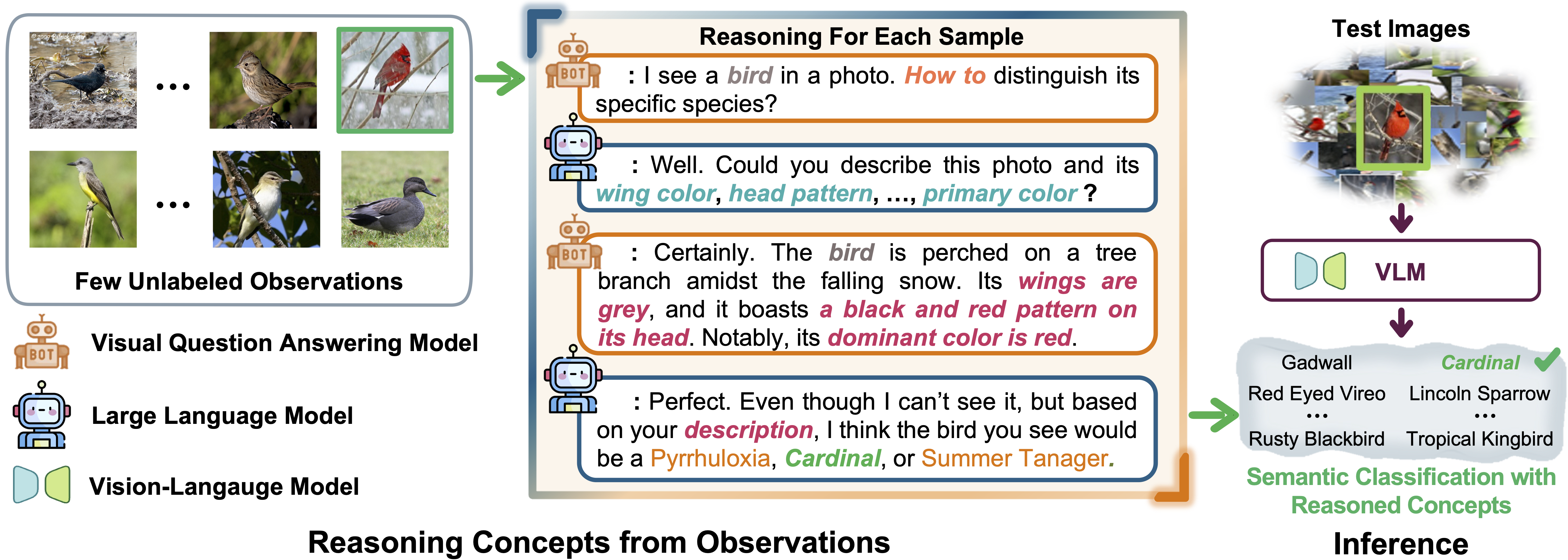
A curious boy encountered a unique challenge when collecting several unlabeled images from a smartphone located in the Amazon jungle. Tasked with identifying the diverse bird species within these images, the boy faced a daunting task, especially without any prior knowledge of species names typically provided by ornithologists.
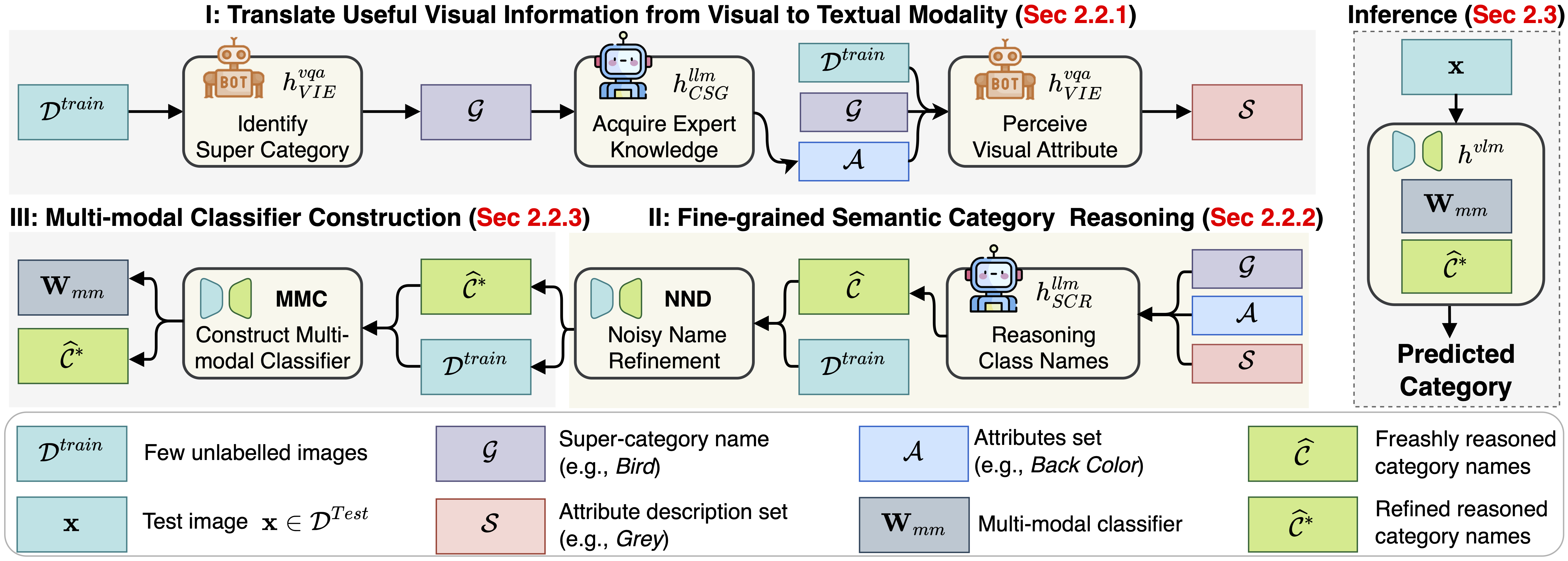
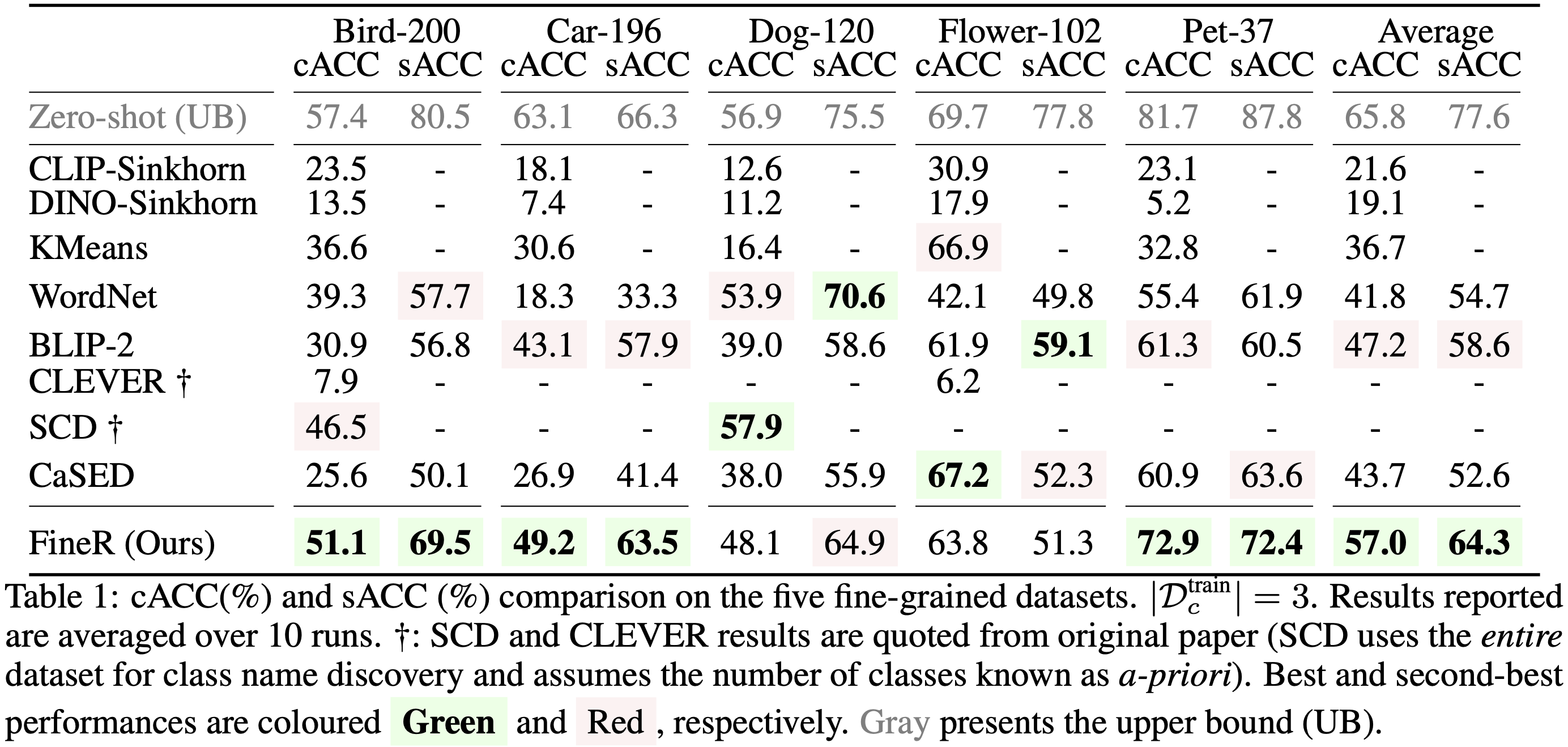
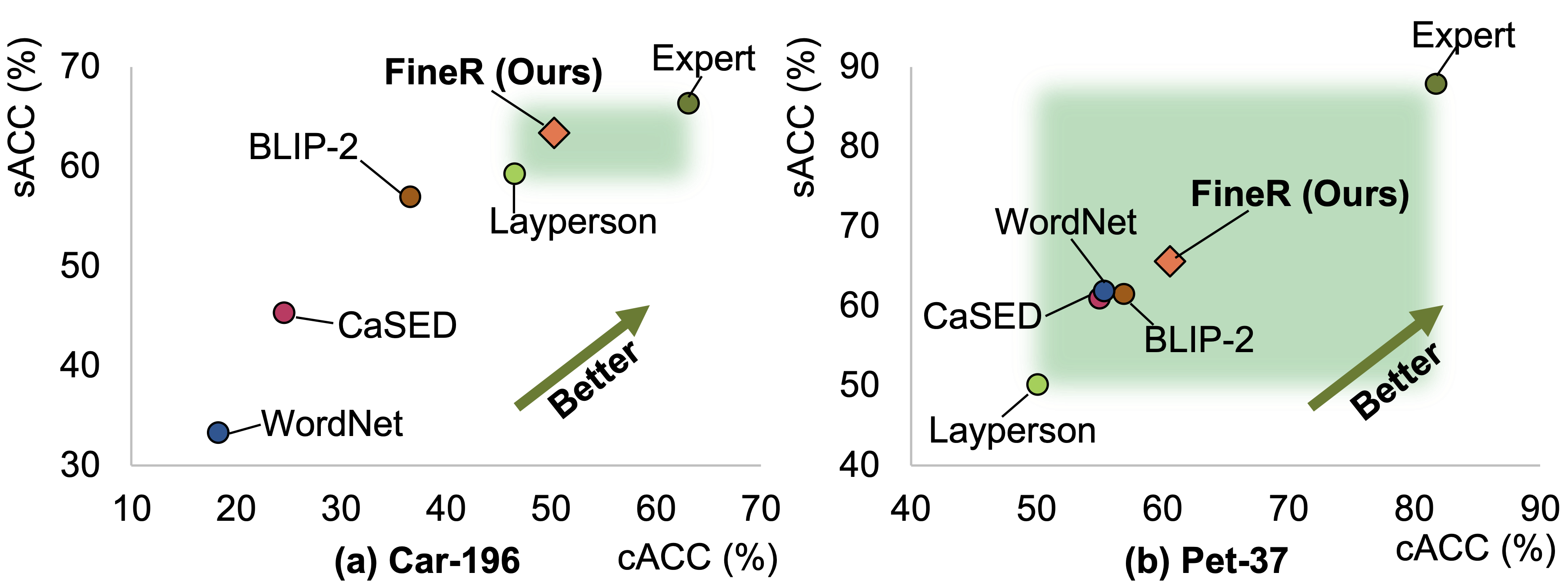
To address this complex challenge, we introduce the FineR system. This novel solution empowers the boy to not only identify but also effectively classify the various bird species captured in the ongoing smartphone camera. FineR is designed to democratize FGVR, freeing the dependence on specialized expert knowledge.